
نصب و راه اندازی سرویس Splunk
فعال سازی لایسنس Splunk License
یکی از قابلیتهای ممتاز اسپلانک را میتوان وجود نسخه تریال رایگان دانست که کاربران به راحتی و مستقیما میتوانند این نسخه تریال دو ماهه را از وبسایت شرکت اسپلانک دانلود و نصب نمایند. این در حالیست که هیچ یک از محصولات رغیب از جمله HP ArcSight و IBM Qradar دارای چنین امکانی نبوده و برای دریافت نسخه تریال می بایستی فرآیند پیچیده ای طی شود. نحوه عملکرد لایسنس اسپلانک نیز کاملا متفاوت از سایر محصولات است. بر خلاف لایسنس سایر محصولات که معمولا بر اساس تعداد لاگ تولید شده درثانیه(EPS) عمل میکنند لایسنس اسپلانک میزان حجم لاگهای ورودی در 24 ساعت را مد نظر قرار می دهد. این قابلیت باعث می شود تیمهای امنیتی محدودیتی در زمینه تعداد تجهیزاتی که لاگهای خود را به سرویس SIEM ارسال می کنند نداشته باشند.
لازم به ذکر است برای استفاده از افزونه های غیر رایگان علاوه بر تهیه لایسنس حجمی نرم افزار اصلی اسپلانک میبایستی برای آن افزونه مورد نظر نیز لایسنس حجمی جداگانه تهیه کرد.در زمینه کاربری SIEM میتوان گفت که حتی تهیه هر دو لایسنس مورد نیاز ( لایسنس Splunk Enterprise و لایسنس افزونه Enterprise Security ) به مراتب هزینه ای پایین تر از محصولات رغیب خواهد داشت.
بیگ دیتا (Big Data) چیست؟
اصل و بنیاد تعریف بیگ دیتا (Big Data) ، تعریفی اقتصادی است. بیگ دیتا از نظر لغوی بهمعنای «داده بزرگ» است و با تجزیه و تحلیل آن میتوان، «الگوهای پنهان»، «همبستگیهای ناشناخته» و سایر اطلاعات مفید را استخراج کرد. در علم اقتصاد، داشتن چنین تحلیلی میتواند منجر به «مزیت نسبی» و جلب سود اقتصادی شود و بازاریابی موثرتر، از جمله بروندادهای این فرآیند تلقی میشود.در بیگ دیتا عموما با دادههایی سر و کار داریم که حجم آنها بیشتر از ظرفیت نرمافزارهای عادی است بنابراین در این پروسه، حجم عظیمی از اطلاعات تفکیک نشده و ساختار نیافته در اختیار قرار میگیرد که ساختاربندی و کشف الگوها از دل آنها کاری دشوار محسوب میشود.
چرا بیگ دیتا (Big Data) اهمیت دارد؟
Big Data اصطلاحی رایج است که رشد و در دسترس بودن داده، چه ساختارمند و چه غیرساختارمند، را توصیف می کند. Big Data ممکن است به اندازه اینترنت برای کسب وکار – و جامعه – مهم باشد. چرا؟ داده های بیشتر به تحلیل های دقیق تر می انجامد. تحلیل های دقیق تر منجر به تصمیم گیریهای مطمئن تری شده و تصمیمات بهتر، می تواند به معنای کارایی بیشتر عملیات، کاهش هزینه ها و کاهش ریسک ها باشد. مسئله واقعی این نیست که مقدار زیادی داده به دست آورید؛ این است که با آن چه می کنید. دیدگاه امیدوارانه این است که سازمان ها قادر به تحصیل داده از هر منبعی بوده، داده های مرتبط را تهیه کرده و آن را تحلیل کنند تا پاسخ سؤالاتی را بیابند که 1) کاهش هزینه ها، 2) کاهش زمان، 3) توسعه محصولات جدید و پیشنهادات جدید، و 4) تصمیم گیری هوشمندانه تر کسب وکار را مقدور می سازند. برای مثال، با ترکیب Big Data و تحلیل های قوی، این امکان وجود دارد تا:
علت های اصلی شکست ها، مسائل و نقوص را در لحظه تعیین کرد تا سالانه تا میلیاردها دلار صرفه جویی کرد.
مسیر وسیله های حمل بسته های تحویلی را زمانی که هنوز در جاده هستند، بهینه کرد.
در چند دقیقه تمام سبد ریسک را دوباره حساب کرد.
سریعاً مشتریانی که بیشترین اهمیت را دارند، شناسایی کرد.
….
Big Data واژه ای است برای مجموعهای از ست داده های بسیار بزرگ و پیچیده، که استفاده از ابزارهای مدیریت پایگاه داده در دست و یا برنامه های کاربردی سنتی پردازش داده، برای پردازش آنها دشوار خواهد بود. چالش ها شامل استخراج، Curation، ذخیره سازی، جستجو، اشتراک، انتقال، آنالیز و بصری سازی است. کار با Big Data با استفاده از سیستم های مدیریت دیتابیس های رابطه ای و بسته های بصری سازی و تحلیل های دسکتاپ، دشوار بوده و نیازمند نرم افزار بسیار موازی در حال کار بر روی ده ها، صدها و یا حتی هزاران سرور هستند. آنچه که Big Data شناخته می شود، بنا بر قابلیت های سازمان مدیریت کننده آن، و قابلیت های برنامه های کاربردی که به طور سنتی در آن زمینه داده پردازش و تحلیل می کنند، متفاوت است. برای برخی سازمان ها، رویارویی با صدها گیگابایت داده برای اولین بار ممکن است نیاز به بازبینی آپشن های مدیریت داده را ایجاد کند. برای برخی دیگر، ممکن است تا ده ها و صدها ترابایت طول بکشد که سایز داده به موضوعی قابل توجه تبدیل شود.
بیگ دیتا (Big Data) در سال 2015
تصور شما از حجم انبوهی از دادهها چیست؟ یک هزارگیگابایت، دهها هزار گیگابایت یا صدها هزار ترابایت! برای سال 2015 میتوان نامهای مختلفی یافت: سال شبکههای اجتماعی، سال محاسبات ابری، سال تبلتها و تلفنهای همراه هوشمند، سال سرویسهای رنگارنگ اینترنتی و بسیاری موارد ریز و درشت دیگر. اما تنها با لحظهای تأمل درخواهیم یافت که استفاده از هر یک از این ابزارهای نرمافزاری و سختافزاری، یک نتیجه واحد در برخواهد داشت: تولید داده و اطلاعات در ابعادی باورنکردنی و غیر قابل تصور…
آمار و ارقامها حاکی از آن است که در حال حاضر، روزانه 2,5 اگزابایت (1,048,576 ترابایت داده و اطلاعات توسط اشخاص و سازمانها تولید میشود و این در حالی است که نود درصد از مجموع دادههای موجود در جهان تنها در طول دو سال گذشته ایجاد شدهاند. پر واضح است که این روند با گسترش روزافزون تعداد کاربران سیستمهای ارتباطی، بدون وقفه و با شیبی مهارناشدنی ادامهیافته و آنچه بیش از هر زمان دیگری اهمیت خواهد داشت، یافتن روشها، ابزارها و مکانیزمهایی برای ذخیره، بازیابی و تحلیل این حجم از داده بهشکلی مؤثر و با کارایی بالا است. رشد فوقالعاده سریع حجم دادهها، اگرچه بهخودی خود فرآیند ذخیرهسازی، بازیابی و تحلیل اطلاعات را دشوار و مواجهه با آن را نیازمند ایجاد ابزارهایی جدید میکند، اما آنچه بحث داده و مکانیزمهای مدیریتی آن را در پایان سال 2015 بهچالشکشیده و بهنوعی رویکرد اصلیسال آینده میلادی را در حوزه پایگاههای داده مشخص میسازد، آگاهی از این حقیقت است که نزدیک به نود درصد از کل دادههای ذخیرهشده در جهان دیجیتال، به نوعي غیر ساختیافته (Unstructured Data) هستند و این موضوع ما را با مفهومی بهنام «داده بزرگ» یا Big Data روبهرومیسازد.
در یک تعریف ساده و بهدور از پیچیدگیهای فنی، «داده بزرگ»، به مجموعههایی از داده (datasets) گفته میشود که نرخ رشد آنها بسیار بالا بوده و در مدت زمان کوتاهی، شامل چنان حجمی از اطلاعات میشوند که دریافت، ذخیرهسازی، جستوجو، تحلیل، بازیابی و همچنین تصویرسازی آنها با ابزارهای مدیریت داده موجود غیر قابل انجام خواهد بود. آنچه حائز اهمیت است، اين است که برخلاف گذشته، مفهوم داده بزرگ تنها مختص به حوزه آکادمیک و حل مسائل علمی مانند شبیهسازیهای پیچیده فیزیکی، تحقیقات زیست محیطی، هواشناسی و مانند آن نبوده و بسیاری از سازمانها و شرکتهاي بزرگ در سالهای آینده با مشکلات مربوط به دادههای انبوه غیرساختیافته يا همان Big Data مواجه خواهند بود.
شواهد فراوانی در اثبات این ادعا وجود دارند که از آن میان میتوان به چهل میلیارد تصویر بارگذاری شده در تنها یکی از شبکههای اجتماعی، ثبت تراکنشهای یک میلیون مشتری در هر ساعت در فروشگاههای زنجیرهای والمارت بهمنظور تحلیل علایق و عادتهای خرید ایشان با حجمی بالغ بر 2,5 پتابایت (هر پتابايت برابر يك هزار ترابايت) و در یک کلام تولید 75 درصد از کل «داده بزرگ» توسط افراد و کاربران معمولی به میزان 1,35 زتابایت (هر زتابايت برابر یک هزار اگزابایت) اشاره کرد. این در حالی است که براساس تحقیقات بهعمل آمده، حجم دادههای موجود در جهان در سال 2015، چهل درصد افزایش یافته و به عددی بالغ بر 2,52 زتابایت خواهد رسید!
پرواضح است که چنین حجمی از داده نیازمندیهای خاص خود را داشته و ابزارهای مختص بهخود را میطلبد. ابزارهایی مانند هادوپ (Hadoop) که بدون تردید جزء موفقترین نمونههای پیادهسازی شده از تفکر NoSQL حسوب میشود. جنبش No SQL که در ابتدا با هدف جایگزینی پایگاههای رابطهای و با شعار پایان رابطهایها (No SQL) خود را معرفیکرد، با مقاومت بزرگان و پشتیبانان مکانیزمهای رابطهای مواجه شد. مقاومتی که باعث شد تا این جنبش نوپا بهدرستی دست از سماجت برداشته و خود را بهعنوان راه حلی مناسب برای مسائلی که پایگاههای داده رابطهای در حل آن با دشواری مواجه هستند، مطرح کند و شعار «نه فقط رابطهای» (Not only SQL) را برای خود برگزیند.
این تغییر رویکرد، شرایط لازم را فراهم آورد تا تمامی فعالان این عرصه از موافق و مخالف بر مزایا و منافع این رویکرد تمرکزکرده و با مشارکت شرکتهایقابل احترامی مانند یاهو و بنیاد آپاچی پروژههایی مانند Hadoop، MangoDB، Cassandra، CouchDB و بسیاری از پروژههاي دیگر، در جهت حل مسائل مرتبط با «داده بزرگ» پا به عرصه حیات بگذارند. رویکردی که بدون کمترین تردیدی در سال 2015 و سالهای بعد از آن، در مرکز توجه بسیاری از شرکتهای تولیدکنندهپایگاههای داده مانند آیبیام، اوراکل، مایکروسافت و دیگران خواهد بود.
کلام پایانی آنکه، سال 2015 را در بحث پایگاههای داده، میتوان بهنوعی سال پردازش دادههای انبوه و غیر ساختیافته و در یک کلام «دادههای بزرگ» دانست. رویکردی که بهجز ابزار و روش، به سختافزارها و پلتفرمهای پر قدرت و قابل اعتماد نیاز داشته و این در شرایطی است که بسیاری از سازمانها و شرکتها، حتی در صورتی که توان مالی خرید چنین تجهیزاتی را در اختیار داشته باشند، از حیث مدیریت، نگهداری و بهروزرسانی و بسیاری مسائل و مشکلات مرتبط با آن، رغبت چندانی به آن نخواهند داشت.این المانهای تصمیمگیری به ظاهر متناقض، در عمل ما را به یاد سرویسهای قابل ارائه در قالب محاسبات ابری (Cloud Computing) انداخته و این نکته را به ذهن متبادر میسازد که نیاز به حجم انبوهی از ماشینهای سرویسدهنده و توان پردازشی فوقالعاده بالا در کنار عدم درگیر شدن با مسائل فنی مرتبط با زیرساختهای مذکور، سال آتی را به مکانی برای قدرتنمایی انواع سرویسهای ابری تبديل كرده و بسیاری از شرکتها به سمت استفاده از آن سوق خواهند یافت.
SIEM چیست؟
SIEM که در لغت به معنای امنیت اطلاعات و مدیریت رویداد نگاری می باشد از مباحث مهم در طراحی یک مرکز عملیات امنیت SOC می باشد. یکی از قسمت های اساسی در هرSOC مبحث SIEM می باشد.
SIEM برگرفته از دو راه حل متفاوت است که شامل:
Security Information Managemen – SIM
Security Event Management – SEM
سیستم SIEM تجزیه تحلیل های Real-Time از هشدارهای امنیتی دستگاه ها و نرم افزارهای شبکه را فراهم می آورد .راه حل های SIEM مشتمل بر نرم افزار ،سخت افزار و سرویس ها ،به منظور وقایع نگاری امنیتی و ارائه گزارش های امنیتی می باشد .کلمات اختصاری SIEM,SEM,SIM را می توان در مواردی به جای یکدیگر به کار برد هر چند که اصولاً معانی متفاوتی دارند.در مباحثی نظیر مدیریت امنیت که با Real-time Monitoring ،وقایع نگاری، هشدارها و مسائلی از این دست سر و کار دارد معمولاً با کلمه SEM همراه می شود.مبحث دیگر که شامل تحلیل و آنالیز Log ها و گزارش دهی می گردد معمولاً به عنوان SIM همراه می شود .
کاربردهای SIEM چیست؟
موارد عمده استفاده از ابزارهای SIEM را می توان در سه حوزه زیر بیان کرد:
Security detective و investigative: این حوزه گاهی لقب threat management را نیز به خود اختصاص می دهد از آنجاییکه بر روی شناسایی و واکنش و در واقع پاسخ به حملات، نفوذ بدافزار ها، دسترسی غیر مجاز به داده ها و اطلاعات و سایر مسائل امنیتی تمرکز دارد.
Compliance regulatory و policy : تمرکز این قسمت بر روی قوانین و سیاست های مورد نیاز و همچنین احکام تعیین شده در سازمان ها می باشد.
Operational, system and network troubleshooting و normal operation: که اغلب بر روی مدیریت log ها تمرکز دارد و با بررسی و یافتن مشکلات سیستم، بمنظور امکان دسترس پذیری سیستم ها و برنامه های کاربردی در صدد رفع این مشکلات بر می آید.
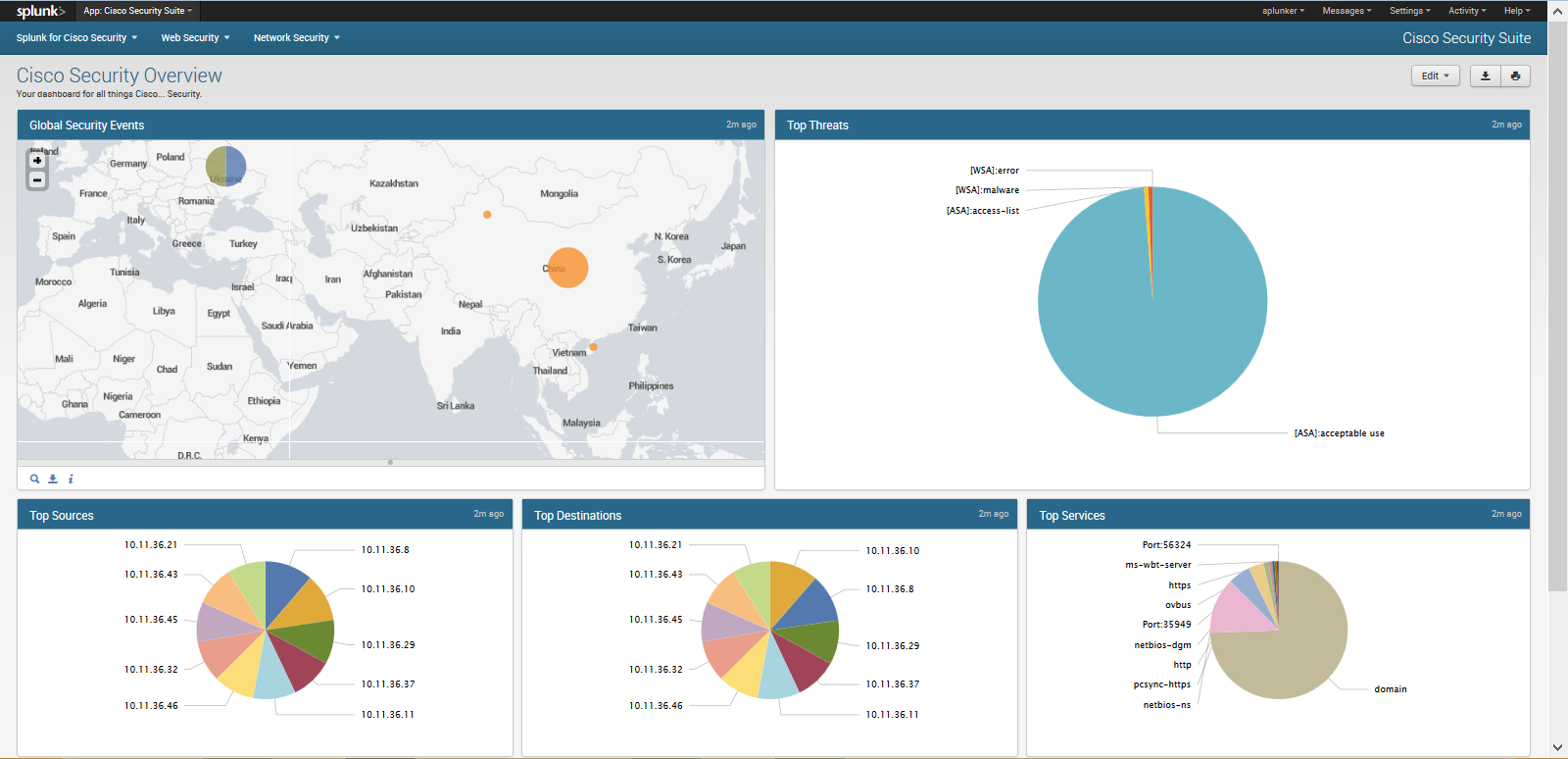
نصب و راه اندازی سرویس Splunk بعنوان راهکار SOC
البته برای بکارگیری سامانه SIEM می توان به چند سناریوی کاربردی در سازمان ها نیز اشاره کرد:
اولین سناریو، SOC و در واقع مرکز عملیات امنیت می باشد که در آن از ویژگی های تکنولوژی SIEM نظیر بررسی و correlation بصورت آنی و لحظه ای استفاده می شود. سازمان با استقرار و توسعه SIEM می تواند تحلیل های آنلاینی بصورت 24*7 داشته باشد و می تواند از هشدارهای امنیتی استفاده کند.
کاربرد دیگر استفاده، در سناریو mini-SOC است. در این موارد پرسنل امنیتی بمنظور چک کردن مسائل امنیتی از بررسی هایی که بصورت آنی و لحظه ای (non real-time) نمی باشد بهره می برند. تحلیلگران فقط در ساعات محدودی از روز بصورت آنلاین هستند و تنها مسئولیت بررسی مجدد هشدارها و گزارش های مورد نیاز را بر عهده دارند.
سناریو بعدی یک automated SOC می باشد که در این صورت سازمان ها SIEM را بصورت alert based مبتنی بر rule ها پیکربندی و تنظیم می کنند و در واقع می توان گفت زمانی به آن توجه میکنند که هشداری از جانب SIEM برای آن ها ارسال شود. در این صورت تحلیلگران در صورت نیاز به بررسی هشدارها و بازبینی مجدد گزارش ها به سراغ آن میروند که این کار میتواند بصورت هفتگی و یا حتی ماهیانه صورت پذیرد. این عملکردی است که بسیاری از سازمان های کوچک خواهان آن هستند و در واقع برای تولید کنندگان ابزار SIEM در مقیاسی کوچک و محدود مطلوب می باشد چرا که امکان سفارشی سازی بطور گسترده برای آن ها وجود ندارد.
تکنولوژی log management دارای نقشی در سناریو های دیگری است که در واقع خارج از حیطه امنیتی می باشند. مدیریت سیستم ها و شناسایی و رفع خطاهای برنامه های کاربردی دو دلیل استفاده از سیستم های مدیریت log ها هستند. با توسعه و پیکربندی برنامه های کاربردی، سیستم مدیریت log ها بمنظور بررسی log های حاصل از آن ها و بررسی خطاها مورد استفاده قرار میگیرد. همچنین این ابزار می تواند بمنظور بررسی رفتار نرمال برنامه های کاربردی و اطمینان از صحت و کارکرد درست آن ها استفاده شوند.
سناریو دیگر برای تکنولوژی log management، گزارش دهی وضعیت انطباق است. (Compliance status reporting) . در این صورت تحلیلگران و یا مدیران امنیتی گزارش ها را با توجه به مسئله compliance مورد بازبینی و بررسی قرار می دهند. این بررسی ها بصورت هفتگی و یا ماهیانه و یا در صورت اعمال قانون و مقررات خاصی صورت می پذیرند. باید توجه کرد که در این شرایط لزوما یک دیدگاه و تمرکز امنیتی و عملکردی (اجرایی) وجود ندارد. این موارد کاربرد عموما بصورت یک فاز گذرا و انتقالی هستند و با احتمال زیادی بسمت سناریو ها و در واقع کاربردهای گسترده تر و بالغ تری حرکت خواهند کرد. در این موارد عموما ابزارهای log management می توانند بسیار مفید واقع شده و استفاده از ابزراهای SIEM چندان رایج نمی باشد. ( برای compliance)
نگهداری log ها بمنظور compliance از اهمیت بالایی برخوردار است اما نگهداری log ها برای طولانی مدت خود بعنوان چالش بزرگی مطرح می شود.
استانداردهای PCI DDS – Payment Card Industry Data Security ، FISMA – Federal Information Security Management Act و HIPAA – Health Insurance Portability and Accountability Act نمونه هایی از این استانداردها بمنظور اعمال Compliance می باشند.
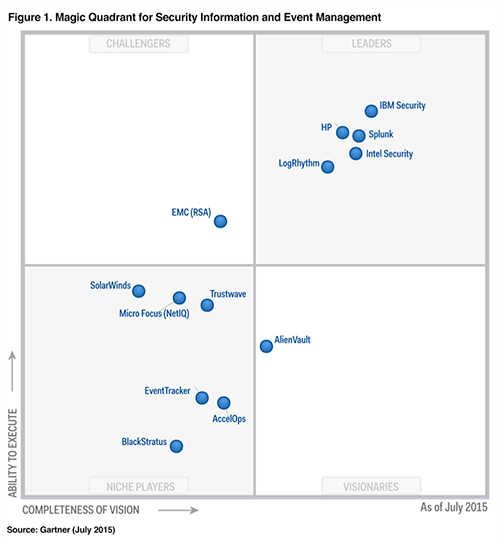
در پایان ذکر این نکته ضروری است که هر سازمان باید با توجه به نیاز خود به تهیه ابزارهای کاربردی اقدام نماید. اما آنچه مهم است این نکته است که امروزه سامانه های SIEM به قدری توانمند شده اند که علاوه بر اینکه بخش Log Management را بصورت یک ماژول مستقل در دل خود دارند بلکه فارغ از اندازه سازمان قابلیت بکارگیری دارند. همینطور نیاز ایجاد و بکارگیری مراکز عملیات امنیت (SOC) بکارگیری سامانه های SIEM را کاملا توجیه پذیر می نماید.شرکتهای مختلفی محصولاتی را در زمینه SIEM ارئه داده اند که از اصلی ترین و کاربرترین آنها میتوان به IBM Qradar, HP ArcSight و Splunk Enterprise اشاره کرد.تمرکز ما بر روی اقتصادی ترین و کاملترین این محصولات یعنی Splunk Enterprise می باشد لذا در ادامه به توضیح و تفصیل این محصول قدرتمند می پردازیم.


